Prevent Crawler from Indexing Sandbox
- via
robots.txtfile:
| |
- (Apache) via
.htaccessfile:
| |
- (Nginx) via
nginx.conffile:
| |
(Optional) Extra Steps if File/Page Already Indexed
If one of the page or file can already be seen on the Google Search result, and you want to remove it, and forbid random user from accessing it, you can do the following:
Forbid public file access:
When using Shield module, it only locks down requests that Drupal is involved in responding to. That exclude static assets (e.g. public files inside
<web-root>/sites/default/files/directory) that the web server would serve directly without bootstrapping Drupal.If you want to block public audience from accessing the files, you can edit the
.htaccessfile in the web root:1 2 3 4 5# Deny access to /sites/default/files/ and its subdirectories <IfModule mod_rewrite.c> RewriteEngine On RewriteRule ^sites/default/files/ - [F,L] </IfModule>1 2 3 4 5# Block direct access to PDF files inside /sites/default/files/ <IfModule mod_rewrite.c> RewriteEngine On RewriteRule ^sites/default/files/.*\.pdf$ - [F,L,NC] </IfModule>
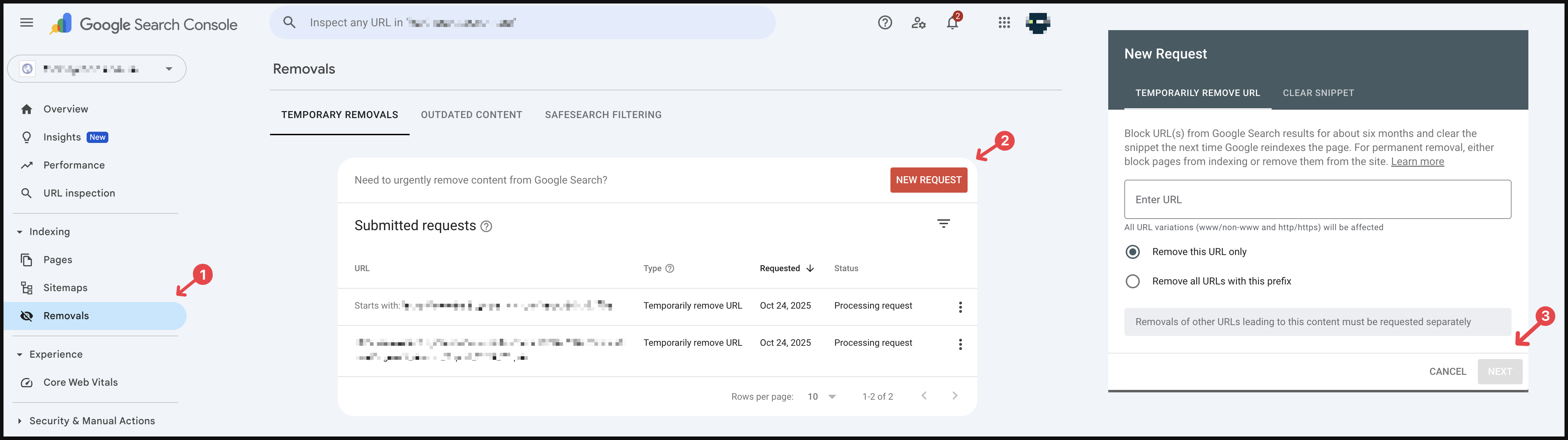
Remove Index from Google Search Console:
If your page is already appearing under search result, you can remove it via Google Search Console’s removals feature:
Reference
- Google Console Support - I want to delete my all indexed data from search console.
- Google Search Central Documentation - Block Search indexing with noindex
- If you wish to move public files to private files, you can refer to this post:
- this article may also be helpful if you want to secure your files in Drupal: