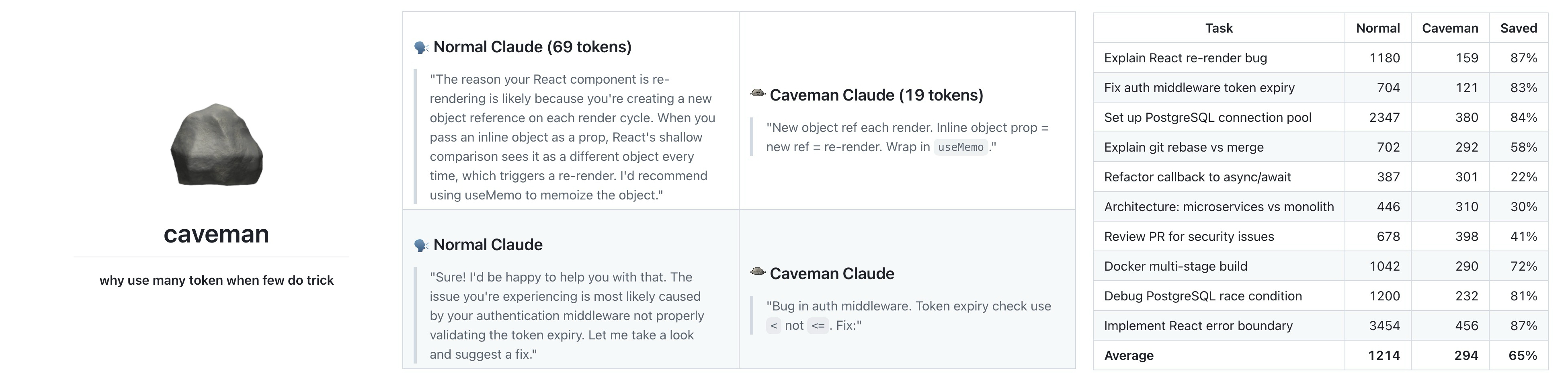
There’s a simple but trending skill on GitHub called “caveman” that does one thing: it tells Claude to stop being polite and just give you the answer. No “certainly! I will help you…” , no long explanations, just the code, the files, the solution, in simple words and short sentences.
While their claim is bold: “~75% fewer output tokens, same technical accuracy”, I feel like I have to test it for myself to figure out exactly how good is it. I will skip the trivial steps when it comes to installation and using skills, you can find those information in the “JuliusBrussee / caveman” GitHub repository.
Benchmark (ran by me !)
I ran the exact same prompt in Claude Code twice once with caveman ON, once with it OFF.
The prompt asked the agent to complete a task to generate Markdown test suite (headings, tables, Mermaid Gantt + flow diagrams, placeholder images, plus several split-by-category files and one master file) for the future use of validating a Markdown-to-CMS migration module.
And below are the outcomes:
| Metric | Caveman OFF 🚫 | Caveman ON ✅ | Saving |
|---|---|---|---|
| Total cost | $1.34 | $0.85 | ~37% |
| Output tokens | 10.9k | 6.4k | ~41% |
| Input tokens | 4.4k | 1.3k | ~70% |
| Cache read | 524.9k | 257.1k | ~51% |
| Cache write | 124.5k | 88.9k | ~29% |
| Lines of code produced | 799 | 505 | — |
- Files generated: file-generated-without-caveman.zip, file-generated-with-caveman.zip
- Steps & Usage comparison: steps-caveman-off.jpeg, steps-caveman-on.jpeg (usage at the very bottom)
- Here’s the original prompt I used in case you’re curious: prompt.txt.
{kind=link}
{kind=link}
The interesting part: the tasks are mostly complete in both runs. Caveman produced fewer lines (505 lines vs 799 lines), but the actual Markdown test files I needed were all there. The caveman skill simply helped me to, skip the chatty scaffolding around them.
Though I have not tested it to the fullest for the more complicated tasks, to ensure it does not make the agent dummer by only allowing them to speak like caveman; and ≈30% saving is still far from the pro-claimed 65% average saving, I would believe it is reasonable to include this as a free win for the type of repetitive dev work where you don’t need much reasoning/planning from the agent.